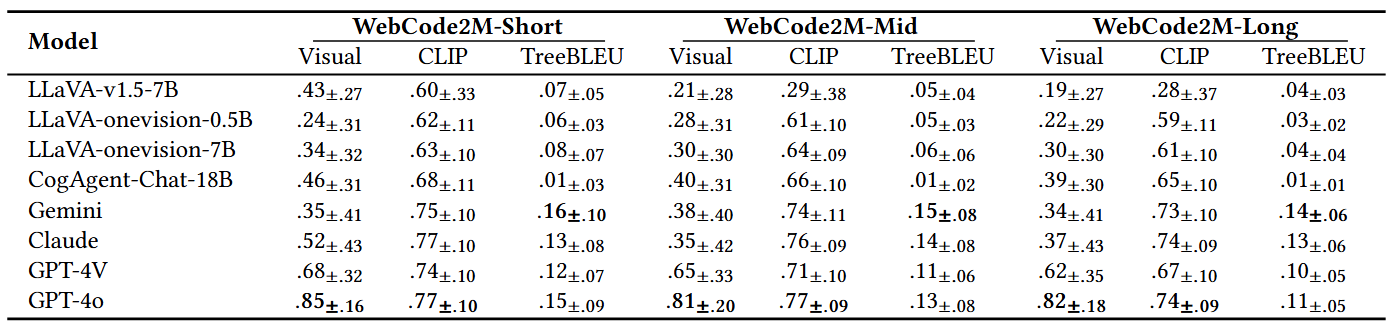
Automatically generating webpage code from webpage designs can significantly reduce the workload of front-end developers, and recent Multimodal Large Language Models (MLLMs) have shown promising potential in this area. However, our investigation reveals that most existing MLLMs are constrained by the absence of high-quality, large-scale, real-word datasets, resulting in inadequate performance in automated webpage code generation. To fill this gap, this paper introduces WebCode2M, a new dataset comprising 2.56 million instances, each containing a design image along with the corresponding webpage code and layout details. Sourced from real-world web resources, WebCode2M offers a rich and valuable dataset for webpage code generation across a variety of user scenarios. dataset quality is ensured by a highly accurate scoring model that filters out instances with aesthetic deficiencies or other incomplete elements. To validate the effectiveness of our proposed dataset, we introduce a baseline model based on the Vision Transformer (ViT), named WebCoder, and establish a benchmark for fair comparison. Additionally, we introduce a new metric, TreeBLEU, to measure the structural hierarchy recall. The benchmarking results demonstrate that our dataset significantly improves the ability of MLLMs to generate code from webpage designs, confirming its effectiveness and usability for future applications in front-end design tools. Finally, we highlight several practical challenges introduced by our dataset, calling for further research. We have hosted the WebCode2M on an anonymous webpage: https://webcode2m-anonymous.github.io.